
In het tijdperk van digitale content zit het onderscheid tussen zichtbaarheid en onduidelijkheid vaak in de details, met name in hoe zoekmachines je website interpreteren.
Inzicht in de fijne kneepjes van robots metatags kan de prestaties van je site in zoekmachines aanzienlijk beïnvloeden. Metatags lijken misschien niet meer dan stukjes code, maar ze vormen de sleutel tot het optimaliseren van de manier waarop je inhoud wordt geïndexeerd en weergegeven.
Robots meta tags dicteren het gedrag van zoekmachines ten opzichte van je webpagina’s en geven aan wat ze moeten crawlen en wat ze moeten negeren.
Met veel richtlijnen, van"index” tot"noindex“, kunnen deze tags de zichtbaarheid van je site vergroten of juist belemmeren.
Navigeren door de verschillende soorten robots meta tags is cruciaal voor het bereiken van een succesvolle SEO strategie.
Deze uitgebreide gids is bedoeld om de complexiteit van robots meta tags in SEO te ontrafelen en biedt inzicht in hun betekenis, typen en best practices voor implementatie.
Of je nu een doorgewinterde webontwikkelaar bent of een nieuwkomer in de wereld van SEO, als je de robots metatags begrijpt, kun je het volledige potentieel ervan benutten voor het succes van je website.
Table of Contents
- Robots meta tags begrijpen
- Het belang van SEO metatags
- Soorten robots metatags
- Algemene meta-robots richtlijnen uitgelegd
- Meta robots "alle" richtlijn
- Meta robots "index" richtlijn
- Meta robots "noindex,follow" richtlijn
- Meta robots "noindex, nofollow" richtlijn
- Meta robots "nofollow" richtlijn
- Meta robots none" richtlijn
- Meta robots "noarchive" richtlijn
- Meta robots "nosnippet" richtlijn
- Meta robots "max-snippet" richtlijn
- Minder belangrijke meta robots richtlijnen
- Meta robots tags op je pagina's implementeren
- WordPress integratie
- Shopify integratie
- X-Robots-Tag instellen op Apache
- X-Robots-Tag configureren op Nginx
- Algemene HTML-implementatie
- Wat is het verschil tussen meta robots, X-Robots en Robots.txt?
- Inzicht in robots directives: ondersteuning voor de populairste zoekmachines
- Conflicterende richtlijnen beheren
- Best practices voor robots meta tags in SEO
- Veelgemaakte fouten vermijden
- De crawlefficiëntie van je website bewaken
Robots meta tags begrijpen
De meta robots tag is een essentieel HTML-element in de sectie van een webpagina dat zoekmachinecrawlers helpt bij het indexeren en crawlen.
De tag gebruikt attributen zoals naam en inhoud om te configureren of een pagina kan worden geïndexeerd, gecrawld of weergegeven in zoekresultaten. Veel voorkomende configuraties zijn “index”,"noindex“,"follow” en"nofollow” richtlijnen.
Als alternatief functioneert de X-Robots-Tag als een HTTP-header, geschikt voor niet-HTML bronnen zoals afbeeldingen en PDF-bestanden, waardoor een bredere controle over diverse bestandstypen mogelijk is.
Om het indexeringsgedrag van webpagina’s efficiënt te beheren, kunnen webmasters serverconfiguratiebestanden, zoals .htaccess voor Apache servers of het hoofdconfiguratiebestand voor Nginx, gebruiken om de X-Robots-Tag header op te nemen.
Zowel de meta robots tag als de X-Robots-Tag zijn cruciaal voor de manier waarop de robots van zoekmachines omgaan met de inhoud van een website, waardoor webmasters strategisch kunnen beheren wat wordt weergegeven in de resultaten van zoekmachines.
Effectief gebruik van deze tags kan de zichtbaarheid en controle van videosnippets, afbeeldingsvoorbeelden en andere inhoudsattributen op zoekmachines zoals Google Search verbeteren.
Een juiste configuratie zorgt ervoor dat niet-HTML bestanden en afbeeldingen volgens de richtlijnen worden behandeld, waardoor onbedoelde indexering van inhoud wordt voorkomen.
Je moet de meta robots directives niet verwarren met robots.txt directives. Dit zijn twee verschillende manieren om met zoekmachines te communiceren over verschillende aspecten van hun crawling- en indexeringsgedrag. Hoewel ze niet hetzelfde zijn, beïnvloeden ze elkaar wel, dus let op! Verderop in dit artikel kun je meer leren over de verschillen.
Het belang van SEO metatags
De robots meta tag speelt een cruciale rol in SEO door te bepalen hoe zoekmachines je website crawlen en indexeren.
Hiermee kun je de presentatie van je inhoud in zoekresultaten beheren en ervoor zorgen dat alleen waardevolle pagina’s worden opgenomen.
Door directives in de robots meta tag te gebruiken, kun je voorkomen dat zoekmachines pagina’s met een lage waarde indexeren, zoals admin- of bedankpagina’s, waardoor je SEO-strategie wordt geoptimaliseerd.
Deze tag biedt meer granulaire controle over het indexeren en crawlen op paginaniveau dan het robots.txt bestand. Je kunt richtlijnen opgeven zoals het al dan niet tonen van resultaten in de cache, het weergeven van snippets en het volgen van links, wat invloed heeft op hoe inhoud wordt weergegeven in zoekresultaten.
Bij gebruik naast robots.txt en sitemaps verbetert de robots meta tag de indexeringsefficiëntie van je website, vooral belangrijk voor grotere of vaak bijgewerkte sites.
Kortom, de robots meta tag is een essentieel hulpmiddel om de SEO van je website gezond te houden.
Het helpt bij het configureren op welke delen van je site de zoekmachine-crawlers zich moeten richten, zodat je SEO-inspanningen behouden blijven en waardevolle inhoud efficiënt wordt geïndexeerd en gepresenteerd aan gebruikers.
Soorten robots metatags
Robots meta directives zijn belangrijk bij het begeleiden van zoekmachine crawlers bij de interactie met de inhoud van je website.
De twee belangrijkste typen zijn de meta robots tag en de X-Robots-Tag. De meta robots-tag is ingebed in de HTML-code van een webpagina en is gericht op indexeringsgedrag op paginaniveau.
De X-Robots-Tag daarentegen werkt op het niveau van de HTTP-header en breidt zijn toepassing uit naar niet-HTML bronnen zoals afbeeldingen en PDF’s. Het is cruciaal om deze tags zorgvuldig te gebruiken om tegenstrijdige richtlijnen te vermijden die zoekmachines kunnen misleiden.
Wat is de meta robots tag
De meta robots tag is een HTML-element in de -sectie van een webpagina dat wordt gebruikt om zoekmachinecrawlers de weg te wijzen.
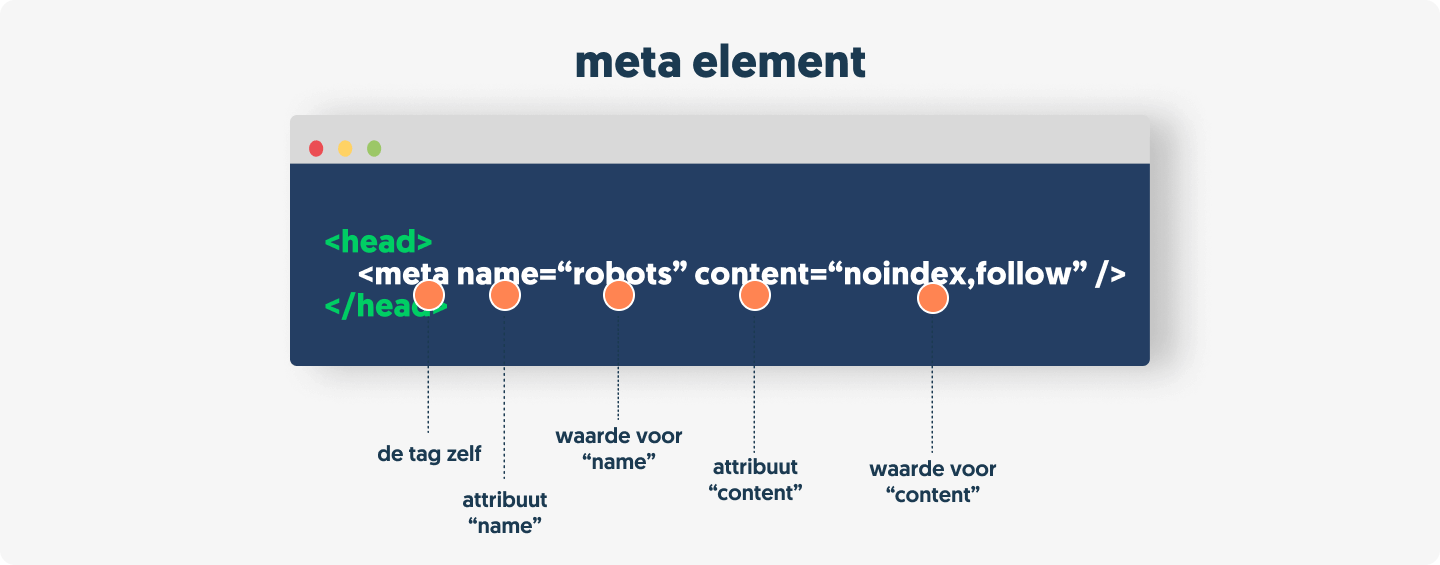
Laten we het bovenstaande voorbeeld van de meta robots richtlijn gebruiken om uit te leggen wat wat is:
- Het hele stukje code wordt het
meta-elementgenoemd. - De
<metaen/>zijn de openings- en sluitingstags. - Er is een attribuut genaamd
namemet de waarderobots.robotsis van toepassing op alle crawlers, maar kan worden vervangen door een specifieke user-agent. - En dan is er een attribuut genaamd
contentmet de waardenoindex,follow.noindex,followkan worden vervangen door andere directives.
Door richtlijnen als noindex of nofollow te gebruiken, kunnen webmasters bepalen of een pagina wel of niet wordt geïndexeerd of dat links worden gevolgd door crawlers.
Deze tag kan meerdere directives tegelijk bevatten en zelfs gericht zijn op specifieke gebruikersagenten van zoekmachines, zoals Googlebot.
Deze flexibiliteit maakt gedetailleerde controle mogelijk over hoe de inhoud van een pagina wordt geïndexeerd en weergegeven in zoekresultaten.
Wat is de X-robots-tag
De X-Robots-Tag werkt, in tegenstelling tot de HTML-gebaseerde meta robots-tag, als een HTTP-header. Dit maakt uitgebreidere controle mogelijk over indexeringsinstructies, die van toepassing zijn op elementen zoals afbeeldingen en PDF-bestanden. De tag wordt server-side geplaatst, binnen configuratiebestanden zoals .htaccess, en ondersteunt geavanceerde functies zoals reguliere expressies voor granulaire controle. Met deze tag kunnen webmasters indexeringsregels globaal of voor specifieke bestandstypen beheren, waardoor de invloed verder gaat dan standaard HTML-inhoud.
Algemene meta-robots richtlijnen uitgelegd
De meta robots tag is een krachtig hulpmiddel dat webmasters gebruiken om aan te geven hoe zoekmachine crawlers zoals Googlebot met specifieke pagina’s moeten omgaan. Door verschillende directives te implementeren, kun je bepalen welke delen van je inhoud worden geïndexeerd, getoond in snippets of privé worden gehouden. Het begrijpen en goed gebruiken van deze directives, zoals die beschikbaar zijn in RankMath SEO of Yoast SEO plugins, is cruciaal voor effectieve zoekmachine optimalisatie (SEO).
Meta robots “alle” richtlijn
De"all directief in de meta robots tag staat zoekmachines expliciet toe om een pagina te indexeren, de links te crawlen en snippets weer te geven, hoewel dit de standaard actie is als er geen andere instructies zijn.
Voor ontwikkelaars die streven naar duidelijkheid, versterkt het gebruik van deze richtlijn dat er geen beperkingen worden gesteld aan de zichtbaarheid van een pagina of de interactie met zoekmachines.
Meta robots “index” richtlijn
De “index” directief wordt gebruikt om zoekmachines te bevestigen dat ze een pagina kunnen indexeren, ook al is dit meestal het standaard gedrag. Het wordt vaak gecombineerd met de"follow” richtlijn() om ervoor te zorgen dat alle links worden gecrawld, waardoor de SEO effectiviteit wordt verbeterd.
Meta robots “noindex,follow” richtlijn
Door"noindex” te combineren met"follow” krijgen zoekmachines toegang tot de links binnen een niet-geïndexeerde pagina en kunnen ze deze gebruiken. Hoewel de pagina hierdoor niet wordt weergegeven in de zoekresultaten, helpt het de linkautoriteit in de hele structuur van de site te behouden.
Meta robots “noindex, nofollow” richtlijn
De “noindex, nofollow” richtlijn() geeft zoekmachines het signaal om de pagina niet te indexeren en de links niet te volgen. Dit is handig voor vertrouwelijke of inhoud die geen waarde toevoegt.
Meta robots “nofollow” richtlijn
Door de richtlijn"nofollow” te gebruiken, worden zoekmachines geïnstrueerd om geen links op de pagina te volgen en dus geen linkautoriteit door te geven. Dit is gunstig voor pagina’s met niet-essentiële of privélinks die je niet wilt onderschrijven.
Meta robots none” richtlijn
De “none” directive combineert"noindex” en"nofollow” in een enkele tag en zorgt ervoor dat zoekmachines geen links op de pagina indexeren of volgen. Ondanks de handige steno, wordt het minder vaak gebruikt vanwege mogelijke misverstanden over de functie.
Meta robots “noarchive” richtlijn
De “noarchive” directief voorkomt dat zoekmachines versies van een webpagina in de cache weergeven in de zoekresultaten. Het kan worden gecombineerd met andere directieven zoals"noindex” en"nofollow” om controle te houden over de interactie van een pagina met zoekmachines.
Meta robots “nosnippet” richtlijn
De richtlijn"nosnippet” geeft zoekmachines de opdracht om geen tekstfragmenten of videovoorbeelden weer te geven in de zoekresultaten en beschermt zo de privacy van de inhoud. De richtlijn kan worden geïmplementeerd naast richtlijnen zoals"noindex” om de weergave van zoekresultaten te regelen.
Meta robots “max-snippet” richtlijn
Met de richtlijn “max-snippet” kunnen webmasters de maximale tekenlengte opgeven van de snippets die worden weergegeven in de zoekresultaten. Door deze op nul in te stellen(max-snippet:0) wordt voorkomen dat er een knipsel wordt weergegeven, wat helpt bij het beheren van de inhoud en het controleren van de presentatie.
Minder belangrijke meta robots richtlijnen
Directives zoals"nosnippet” en"max-snippet:[nummer]” passen de weergave in zoekresultaten aan, maar hebben over het algemeen minder invloed op de algehele indexering van de site in vergelijking met belangrijkere tags zoals"noindex“.
Toch dragen ze bij aan gedetailleerde optimalisatiestrategieën, zodat zoekmachines crawlbudgetten effectief gebruiken en zich richten op waardevolle site-inhoud. Bekijk zeker de volgende bronnen van de verschillende zoekmachines voor meer informatie:
- Meta Robots documentatie bij Google
- Meta Robots-documentatie bij Bing
- Meta Robots documentatie bij Yandex
Meta robots tags op je pagina’s implementeren
Een meta robots tag is cruciaal om zoekmachine crawlers te instrueren hoe ze webpagina’s moeten indexeren en weergeven in zoekresultaten.
Deze tag, die in de -sectie van een webpagina wordt geplaatst, gebruikt richtlijnen als “noindex” en “nofollow” om te bepalen welke pagina’s en links worden geïndexeerd.
Het gebruik van een meta robots tag of een X-Robots tag is voldoende; het gebruik van beide verhoogt de effectiviteit niet.
Je kunt het aanpassen van de meta robots tag op meerdere pagina’s stroomlijnen via de SEO-instellingen van je site, zodat je het indexeringsgedrag efficiënt kunt afstemmen. Als alternatief biedt de X-Robots tag meer flexibiliteit door het indexeren op zowel paginaniveau als voor specifieke elementen te beheren.
WordPress integratie
In WordPress is het opnemen van meta robots tags vereenvoudigd met SEO plugins zoals Yoast SEO en RankMath.
Met deze plugins kunnen gebruikers eenvoudig indexeringsrichtlijnen beheren via intuïtieve interfaces. Met Yoast SEO kunnen gebruikers met de optie “Sta zoekmachines toe om dit bericht te tonen in zoekresultaten?” direct het kenmerk"noindex” instellen.
RankMath biedt een vergelijkbare functie via de optie No Index onder het tabblad Geavanceerd. Voor degenen die de voorkeur geven aan handmatige configuratie, is het bewerken van de HTML van de site in de sectie ook een optie.
Yoast SEO’s geavanceerde instellingen maken uitgebreid richtlijnbeheer mogelijk, inclusief"noindex” en"noimageindex”
Shopify integratie
Om meta robots tags in Shopify te implementeren, kunnen gebruikers de sectie van hun theme.liquid layout bestand aanpassen.
Dit geeft precieze controle over hoe zoekmachines met hun site omgaan. Shopify integreert met Yoast SEO, wat gebruikers helpt bij het effectief beheren van zoekmachine indexering en crawling.
Door specifieke meta robots tags aan te passen, kunnen Shopify gebruikers zoekmachines opdracht geven om bepaalde pagina’s of links te negeren. Het proces vereist minimale HTML-aanpassingen om de gewenste richtlijnen in te stellen.
Yoast SEO voor Shopify biedt een intuïtieve interface voor het selecteren van robots directives, waardoor het makkelijker wordt voor winkeleigenaren om de zichtbaarheid van hun site in zoekmachines te overzien.
X-Robots-Tag instellen op Apache
De X-Robots-Tag is een HTTP-header die meer flexibiliteit biedt bij het regelen van zoekmachinegedrag dan de traditionele meta robots tag. Deze tag kan worden toegepast op verschillende inhoudstypen, waaronder HTML, PDF’s, afbeeldingen en meer, waardoor het een veelzijdig hulpmiddel is voor webmasters die willen beheren hoe hun inhoud wordt geïndexeerd.
Als je een Apache server gebruikt, kun je de X-Robots-Tag configureren door je .htaccess bestand aan te passen. Het proces is eenvoudig en bestaat uit het toevoegen van specifieke richtlijnen. Dit is hoe je het kunt doen:
- Ga naar je .htaccess-bestand: Maak eerst verbinding met je server met een FTP-client of via je hostingcontrolepaneel. Zoek en open het
.htaccessbestand in de hoofdmap van je website. - X-Robots-Tag richtlijnen toevoegen: Je kunt de volgende syntaxis gebruiken om de richtlijnen op te geven die je wilt gebruiken. Om bijvoorbeeld te voorkomen dat een specifieke map wordt geïndexeerd, kun je toevoegen:
<Directory "/path/to/directory">
Header set X-Robots-Tag "noindex, nofollow"
</Directory>
Als je de tag wilt toepassen op alle PDF-bestanden die door je site worden geserveerd, kun je het volgende gebruiken:
<FilesMatch ".pdf$">
Header set X-Robots-Tag "noindex"
</FilesMatch>
- Gebruik voor specifieke pagina’s of bestanden: De X-Robots-Tag kan ook gericht worden op individuele bestanden. Als je bijvoorbeeld wilt voorkomen dat een bepaalde HTML-pagina wordt geïndexeerd, kun je de volgende regel rechtstreeks in je
.htaccessinvoegen:
<Files "voorbeeld-pagina.html">
Header set X-Robots-Tag "noindex, nofollow"
- Test je wijzigingen: Nadat je je wijzigingen hebt aangebracht, sla je het bestand op en controleer je of het correct is geüpload naar je server. Je kunt controleren of de X-Robots-Tag werkt zoals bedoeld door verschillende online tools of tools voor browserontwikkelaars te gebruiken om de HTTP-headers van je pagina’s en bestanden te inspecteren.
- Controleer je SEO prestaties: Het is belangrijk om in de gaten te houden hoe je aanpassingen de indexering en het organische verkeer beïnvloeden. Gebruik tools zoals Google Search Console om de impact van je X-Robots-Tag implementatie op de aanwezigheid van je site in de zoekresultaten bij te houden.
Door de X-Robots-Tag effectief te configureren op je Apache server, kun je meer controle krijgen over de SEO prestaties van je website en ervoor zorgen dat zoekmachines alleen de inhoud indexeren die jij wilt dat ze indexeren. Deze flexibiliteit kan vooral gunstig zijn voor websites met een grote verscheidenheid aan inhoudstypen en beheerprioriteiten.
X-Robots-Tag configureren op Nginx
Als je website gehost wordt op een Nginx server, is het configureren van de X-Robots-Tag een beetje anders dan op Apache, maar het is net zo eenvoudig. Volg deze stappen om de X-Robots-Tag directives toe te voegen aan je Nginx configuratie:
- Toegang tot je Nginx configuratiebestand: Eerst moet je verbinding maken met je server via SSH of een bestandsbeheerder van je hostingdienst gebruiken om toegang te krijgen tot het Nginx configuratiebestand. Het primaire bestand bevindt zich vaak in
/etc/nginx/nginx.conf, of soms in desites-availablemap voor specifieke sites. - X-Robots-Tag richtlijnen toevoegen: Je kunt de X-Robots-Tag toevoegen in het serverblok voor je specifieke domein of in een locatieblok. Hier zie je hoe je kunt voorkomen dat een specifieke directory wordt geïndexeerd:
location /path/to/directory {
add_header X-Robots-Tag "noindex, nofollow";
}
Voor het targeten van alle PDF-bestanden die door je site worden geserveerd met een noindex-richtlijn, kun je de volgende syntaxis gebruiken:
locatie ~* .pdf$ {
add_header X-Robots-Tag "noindex";
}
Om de tag op een specifieke HTML-pagina toe te passen, kun je het als volgt doen:
locatie = /voorbeeld-pagina.html {
add_header X-Robots-Tag "noindex, nofollow";
}
- Sla je configuratie op en test deze: Zodra je de vereiste richtlijnen hebt toegevoegd, sla je het configuratiebestand op. Het is cruciaal om de configuratie te testen op syntaxfouten voordat je deze toepast. Je kunt dit doen met het volgende commando in je terminal:
nginx -t
Als de test succesvol is, laad dan Nginx opnieuw om de wijzigingen toe te passen:
sudo systemctl reload nginx
- Controleer de wijzigingen: Om te bevestigen dat je X-Robots-Tag directives correct werken, gebruik je tools zoals de Developer Tools van de browser om de HTTP headers van je pagina’s en bestanden te inspecteren. Je kunt ook online HTTP header checkers gebruiken om te controleren of de juiste tags worden verzonden.
- Controleer SEO-effecten: Net als bij een Apache setup is het essentieel om te controleren hoe deze wijzigingen je SEO prestaties beïnvloeden. Gebruik Google Search Console en andere analyseprogramma’s om veranderingen in de indexeringsstatus en het organische verkeer van je website bij te houden.
Algemene HTML-implementatie
Een meta robots tag is een HTML-component in de -sectie die zoekmachinecrawlers begeleidt bij het indexeren, crawlen en weergeven van pagina’s.
De X-Robots tag dient op vergelijkbare wijze als een HTTP-header, maar is van toepassing op niet-HTML bestanden zoals afbeeldingen en PDF’s.
Het content attribuut van de tag bevat directieven zoals “noindex” en “nofollow”, die controle geven over het indexeren en crawlen van links. Google ondersteunt aanvullende directives zoals “noarchive”, waarmee wordt voorkomen dat versies in de cache worden weergegeven in de zoekresultaten, en “notranslate”, waarmee wordt voorkomen dat er vertalingen worden aangeboden.
Het combineren van directives in een enkele tag maakt genuanceerde controle mogelijk, zoals in .
Wat is het verschil tussen meta robots, X-Robots en Robots.txt?
De meta robots-tag en de X-Robots-Tag hebben een vergelijkbare functie door zoekmachinecrawlers te instrueren hoe ze het indexeren van webpagina’s moeten aanpakken. De meta robots tag is ingebed in de HTML van een pagina, terwijl de X-Robots-Tag deel uitmaakt van de HTTP-responsheaders en flexibiliteit biedt voor niet-HTML bronnen zoals PDF- en videobestanden.
Er is er maar één nodig per URL om onnodige complexiteit te voorkomen.
Robots.txt, te onderscheiden van de tags, vertelt zoekmachine-crawlers welke pagina’s niet geopend mogen worden, maar heeft geen invloed op hoe geïndexeerde inhoud in zoekresultaten wordt weergegeven.
Het gebruik van robots.txt kan voorkomen dat zoekmachines noindex directives in de meta robots tag zien, wat mogelijk leidt tot onverwachte indexering van inhoud.
Het opnemen van een noindex-richtlijn met een canonieke URL kan zoekmachines verwarren met tegenstrijdige instructies over de indexering van een pagina. Om het indexeren effectief te beheren, kies je op basis van je behoeften tussen meta robots en X-Robots-Tag en vermijd je overbodige directives.
Optimaliseer de zichtbaarheid en het indexeringsgedrag van je site met een zorgvuldige configuratie, vaak met behulp van SEO plugins zoals RankMath of Yoast SEO.
Inzicht in robots directives: ondersteuning voor de populairste zoekmachines
Als het gaat om het optimaliseren van je website voor zoekmachines, kan inzicht in de manier waarop verschillende robots directives worden geïnterpreteerd een aanzienlijk verschil maken in de zichtbaarheid van je site.
Robots directives zijn instructies die je aan zoekmachines kunt geven om aan te geven hoe ze je inhoud moeten crawlen en indexeren.
Niet elke zoekmachine interpreteert deze richtlijnen echter op dezelfde manier en de ondersteuning voor verschillende richtlijnen kan verschillen.
Hieronder vind je een uitgebreide tabel met de ondersteuning voor verschillende robots directives bij Google, Bing/Yahoo en Yandex.
| Directive | Bing/Yahoo | Yandex | |
|---|---|---|---|
| all | ✅ | ✅ | ✅ |
| index | ✅ | ✅ | ✅ |
| follow | ✅ | ✅ | ✅ |
| noindex | ✅ | ✅ | ✅ |
| nofollow | ✅ | ✅ | ✅ |
| none | ✅ | ✅ | ✅ |
| noarchive | ✅ | ✅ | ✅ |
| nosnippet | ✅ | ✅ | ✅ |
| max-snippet | ✅ | ❌ | ❌ |
| unavailable_after | ✅ | ❌ | ❌ |
| noimageindex | ✅ | ❌ | ❌ |
| max-image-preview | ✅ | ❌ | ❌ |
| max-video-preview | ✅ | ❌ | ❌ |
| notranslate | ✅ | ❌ | ❌ |
- Universele ondersteuning: Directives zoals
all,index,follow,noindex,nofollow,none,noarchiveennosnippetworden universeel ondersteund door alle drie de grote zoekmachines: Google, Bing/Yahoo en Yandex. - Beperkte ondersteuning: Verschillende richtlijnen, waaronder
max-snippet,unavailable_after,noimageindex,max-image-preview,max-video-previewennotranslate, worden alleen ondersteund door Google en niet door Bing/Yahoo of Yandex.
Het begrijpen van deze verschillen is essentieel voor het effectief afstemmen van je SEO-strategie, zodat je het gewenste crawling- en indexeringsgedrag communiceert aan zoekmachines die het belangrijkst zijn voor je zichtbaarheid.
Conflicterende richtlijnen beheren
Het beheren van conflicterende directives in meta robots tags is cruciaal voor effectieve SEO. Wanneer richtlijnen als “index” en “noindex” beide worden toegepast, kunnen crawlers van zoekmachines in verwarring raken.
Google kiest standaard voor de meest beperkende richtlijn en kiest voor “noindex” als beide richtlijnen bestaan, waardoor de pagina niet wordt geïndexeerd ondanks andere instructies.
Het is essentieel om zowel de robots metatags als de X-Robots-Tag zorgvuldig te configureren om te voorkomen dat de indexering van pagina’s onbedoeld wordt geblokkeerd.
Verschillende zoekmachines, zoals Yandex, kunnen anders omgaan met dergelijke scenario’s, waardoor een pagina mogelijk wel wordt geïndexeerd, maar Google niet. Tegenstrijdige richtlijnen kunnen de zichtbaarheid van je site op deze platforms bemoeilijken.
Als je meerdere meta-elementen gebruikt, is het aan te raden om user-agents te specificeren, die op maat gemaakte instructies geven aan verschillende crawlers van zoekmachines. Er kunnen echter nog steeds conflicten optreden als deze niet goed worden beheerd.
Om ervoor te zorgen dat zoekmachinerobots en crawlers je richtlijnen goed begrijpen, moet je voorkomen dat tegenstrijdige instructies door elkaar worden gebruikt en zorgen voor duidelijke en beknopte opdrachten in je SEO configuratiebestanden.
Een goed beheer van deze richtlijnen zal de zichtbaarheid van je content in de zoekresultaten verbeteren.
Best practices voor robots meta tags in SEO
De meta robots tag, geplaatst in de sectie van een webpagina, begeleidt zoekmachinerobots bij het indexeren en weergeven van inhoud in zoekresultaten.
Om de SEO prestaties te verbeteren, is het cruciaal om te voorkomen dat pagina’s die weinig waarde bieden, zoals beheerinterfaces, bedankberichten of dubbele inhoud, worden geïndexeerd.
Door zoekmachine crawlers specifieke instructies te geven, wordt het risico op standaard gedrag dat SEO negatief beïnvloedt geminimaliseerd.
Strategisch gebruik van meta robots tags geeft meer controle over hoe pagina’s worden gecrawld en geïndexeerd, vooral handig voor pagina’s die niet bedoeld zijn om organisch verkeer aan te trekken.
Het combineren van meerdere directives binnen de tag biedt de flexibiliteit om de zichtbaarheid van inhoud en de instellingen voor het weergeven van snippets te beheren.
Het toepassen van"noindex” voorkomt bijvoorbeeld dat pagina’s in zoekresultaten verschijnen, terwijl"nofollow” voorkomt dat links op een pagina worden gevolgd.
Uiteindelijk beschermt effectief gebruik van meta robots directives zoals"noindex” of"nofollow” tegen verouderde inhoud en technische pagina’s die de zichtbaarheid van je site in de zoekresultaten schaden.
Het is een strategisch hulpmiddel om het indexeringsgedrag af te stemmen op specifieke SEO-doelen, zodat alleen waardevolle inhoud wordt weergegeven in de zoekmachineresultaten.
Veelgemaakte fouten vermijden
Bij het beheren van SEO voor je website is het cruciaal om veelgemaakte fouten met meta robots tags en X-Robots-Tag directives te vermijden.
Ten eerste moet je ervoor zorgen dat deze tags niet worden geplaatst op pagina’s die worden geblokkeerd door robots.txt-bestanden, omdat geblokkeerde pagina’s deze instellingen zullen negeren. Dit kan ertoe leiden dat je directives worden genegeerd, met alle gevolgen van dien voor de crawlbaarheid van je site.
Voeg geen noindex directives toe aan je robots.txt bestand, want deze methode wordt niet langer ondersteund door Google en kan leiden tot indexeringsproblemen. Het is ook belangrijk om ervoor te zorgen dat je meta robots tags en X-Robots-Tag directives zonder conflicten op elkaar zijn afgestemd.
Inconsistente directives kunnen zoekmachines in verwarring brengen, waardoor het onduidelijk wordt hoe je wilt dat je pagina’s worden gecrawld en geïndexeerd.
Het ontbreken van een robots meta tag kan er onbedoeld voor zorgen dat pagina’s worden geïndexeerd, waardoor mogelijk gevoelige informatie wordt blootgelegd of dubbele inhoud wordt gecreëerd. Bovendien kan het niet opnemen van een nofollow richtlijn ervoor zorgen dat zoekmachines link equity doorgeven aan bepaalde pagina’s, wat een negatieve invloed kan hebben op SEO prioriteiten.
Het regelmatig controleren van je SEO-configuratie kan helpen om een responsieve en effectieve indexeringsstrategie te behouden.
De crawlefficiëntie van je website bewaken
Om een optimale crawl-efficiëntie te garanderen, is het cruciaal om meta robots en X-Robots-Tag richtlijnen correct te configureren. Deze richtlijnen geven zoekmachine-crawlers aan hoe ze moeten omgaan met de inhoud van webpagina’s, waardoor de zichtbaarheid in zoekmachineresultaten wordt gemaximaliseerd.
Misstappen, zoals het laten staan van oude noindex directives op belangrijke pagina’s, kunnen leiden tot indexeringsproblemen en afname van verkeer.
Het gebruik van de robots meta tag voor HTML-pagina’s en de X-Robots-Tag voor niet-HTML bronnen (zoals PDF’s en afbeeldingen) biedt nauwkeurige controle over het indexeringsgedrag van zoekmachines.
Het regelmatig controleren van je site met SEO tools zoals RankMath SEO of Yoast SEO kan helpen bij het identificeren van crawlfouten en verkeerde instellingen van richtlijnen die de prestaties kunnen beïnvloeden.
Een veel voorkomende fout is het blokkeren van pagina’s met zowel noindex tags als verboden vermeldingen in een robots.txt bestand.
Dit voorkomt dat crawlers pagina’s opnieuw bezoeken en bijgewerkte richtlijnen toepassen, zoals het verwijderen van noindex-tags zodra een pagina live gaat. Het implementeren van best practices en het uitvoeren van routinecontroles zorgt voor efficiënt crawlen en indexeren, wat uiteindelijk de zoekprestaties van je site verbetert.
In een snel evoluerend digitaal landschap is het effectief gebruiken van meta robots tags essentieel voor het beheren van hoe je inhoud wordt geïndexeerd en gecrawld door zoekmachines.
Door de juiste richtlijnen toe te passen en je website regelmatig te controleren, houd je controle over de zichtbaarheid van je site en optimaliseer je tegelijkertijd de zoekprestaties.
Uiteindelijk helpt het navigeren door de nuances van meta robots niet alleen bij het voorkomen van indexeringsfouten, maar verbetert het ook je algehele SEO-strategie.
Het omarmen van deze praktijken helpt bij een betere communicatie met zoekmachines en zorgt ervoor dat je website zijn volledige potentieel bereikt in de zoekresultaten.